Problems tagged with "SVMs"
Problem #011
Tags: SVMs
Let \(X = \{\nvec{x}{i}, y_i\}\) be a data set of \(n\) points where each \(\nvec{x}{i}\in\mathbb R^d\).
Let \(Z = \{\nvec{z}{i}, y_i\}\) be the data set obtained from the original by standardizing each feature. That is, if a matrix were created with the \(i\)th row being \(\nvec{z}{i}\), then the mean of each column would be zero, and the variance would be one.
Suppose that \(X\) and \(Z\) are both linearly-separable. Suppose Hard-SVMs \(H_1\) and \(H_2\) are trained on \(X\) and \(Z\), respectively.
True or False: \(H_1(\nvec{x}{i}) = H_2(\nvec{z}{i})\) for each \(i = 1, \ldots, n\).
Solution
False.
This is a tricky problem! For an example demonstrating why this is False, see: https://youtu.be/LSr55vyvfb4
Problem #013
Tags: SVMs
The image below shows a linear prediction function \(H\) along with a data set; the ``\(\times\)'' points have label +1 while the ``\(\circ\)'' points have label -1. Also shown are the places where the output of \(H\) is 0, 1, and -1.
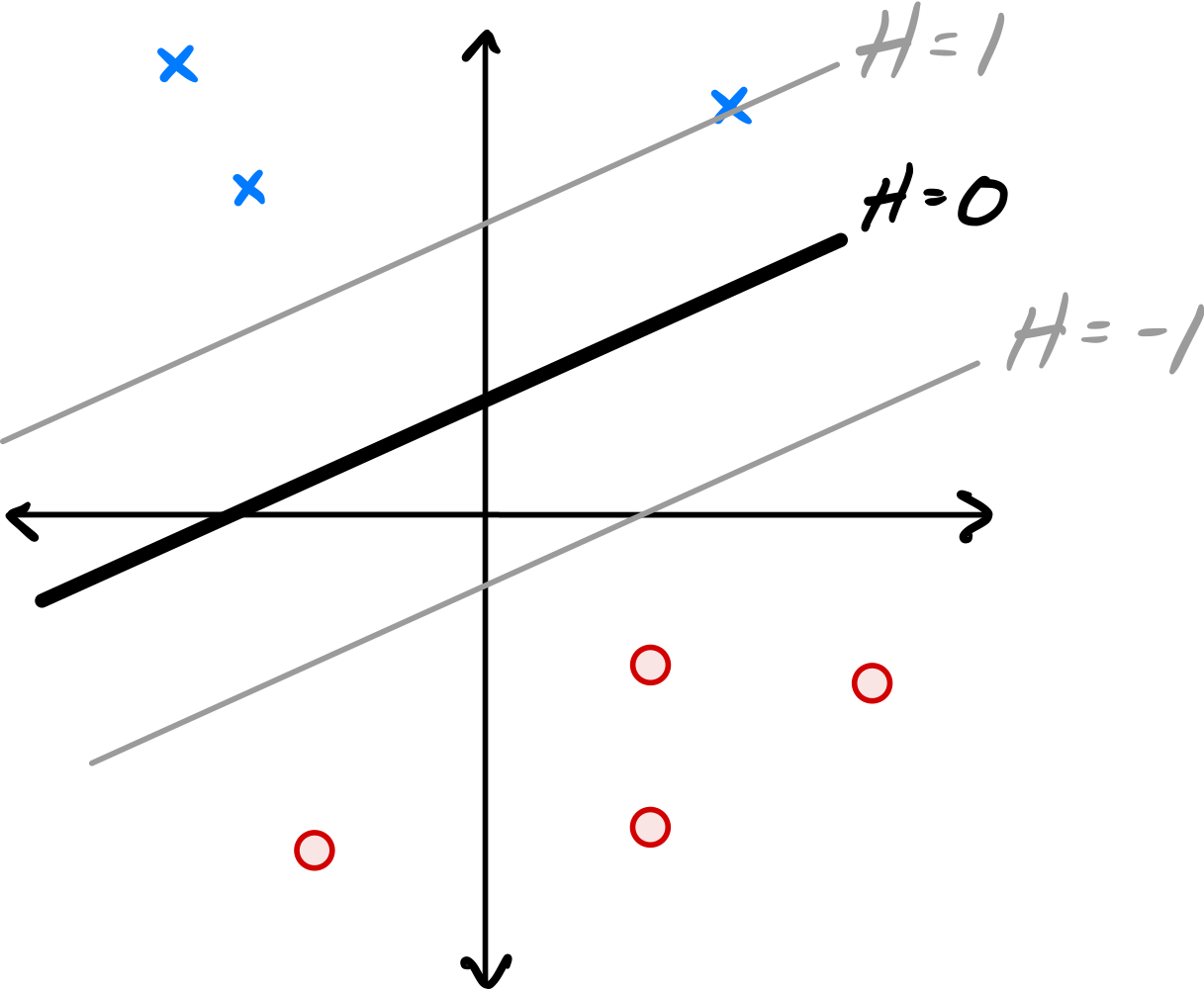
True or False: \(H\) could have been learned by training a Hard-SVM on this data set.
Solution
False.
The solution to the Hard-SVM problem is a hyperplane that separates the two classes with the maximum margin.
In this solution, the margin is not maximized: There is room for the ``exclusion zone'' between the two classes to grow, and for the margin to increase.
Problem #027
Tags: SVMs
Suppose a data set \(\mathcal D\) is linearly separable. True or False: a Hard-SVM trained of \(\mathcal D\) is guaranteed to achieve 100\% training accuracy.
Solution
True.
Problem #029
Tags: SVMs
The image below shows a linear prediction function \(H\) along with a data set; the ``\(\times\)'' points have label +1 while the ``\(\circ\)'' points have label -1. Also shown are the places where the output of \(H\) is 0, 1, and -1.
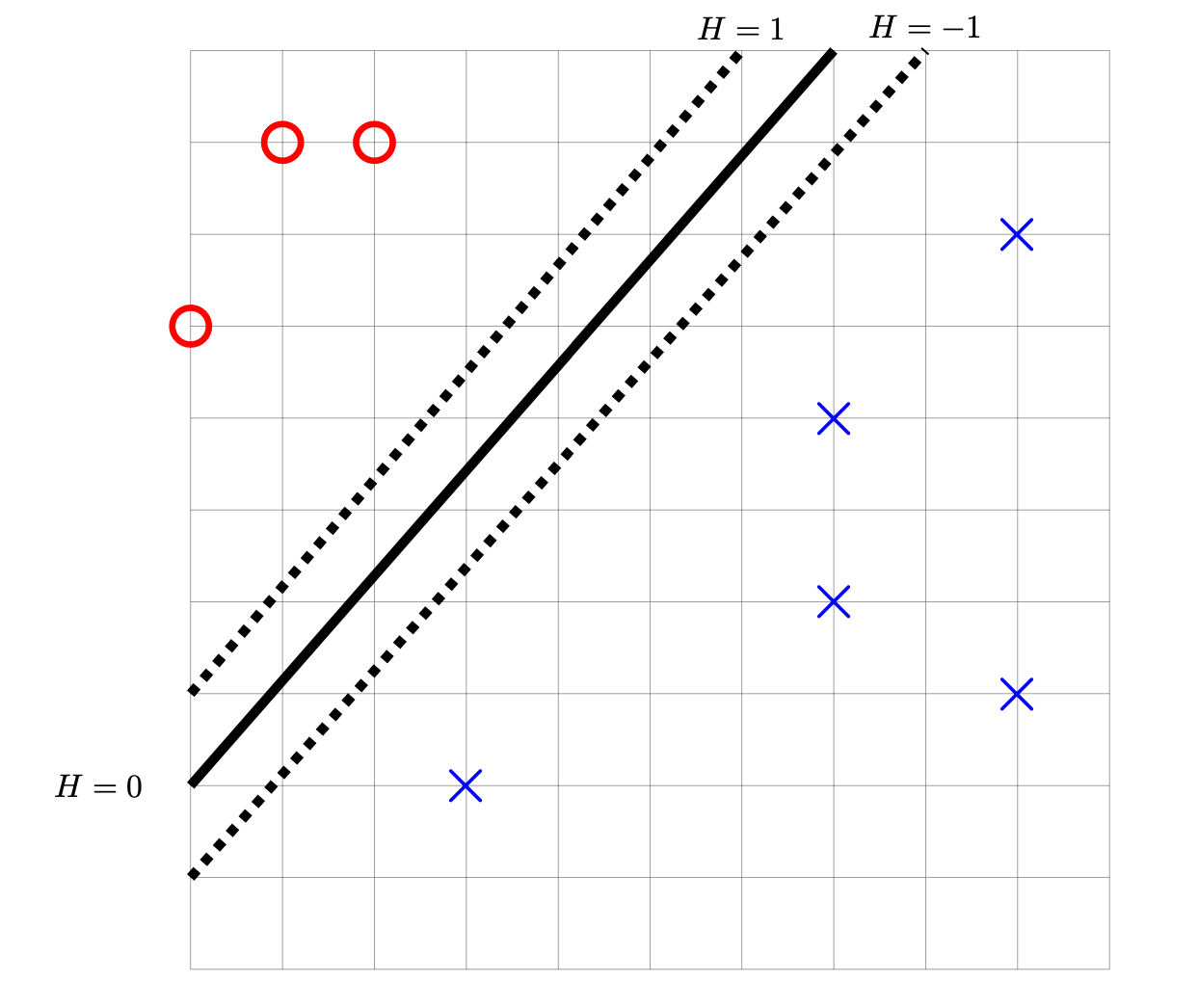
True or False: \(H\) could have been learned by training a Hard-SVM on this data set.
Solution
False.
Problem #071
Tags: SVMs
In lecture, we saw that SVMs minimize the (regularized) risk with respect to the hinge loss. Now recall, the 0-1 loss, which was defined in lecture as:
Part 1)
Suppose a Hard SVM is trained on linearly-separable data. True or False: the solution is guaranteed to have the smallest 0-1 risk of any possible linear prediction function \(H(\vec x) = \vec w \cdot\operatorname{Aug}(\vec x)\).
Solution
True. If the data is linearly seperable, then a Hard-SVM will draw a decision boundary that goes between the two classes, perfectly classifying the training data and achieve a 0-1 risk of zero.
Part 2)
Suppose a Soft SVM is trained on linearly-separable data using an unknown slack parameter \(C\). True or False: the solution is guaranteed to have the smallest 0-1 risk of any possible linear prediction function \(H(\vec x) = \vec w \cdot\operatorname{Aug}(\vec x)\).
Solution
False.
Part 3)
Suppose a Soft SVM is trained on data that is not linearly separable using an unknown slack parameter \(C\). True or False: the solution is guaranteed to have the smallest 0-1 risk of any possible linear prediction function \(H(\vec x) = \vec w \cdot\operatorname{Aug}(\vec x)\).
Solution
False.
Problem #073
Tags: SVMs
Consider the data set shown below. The points marked with ``+'' have label +1, while the ``\(\circ\)'' points have label -1. Shown are the places where a linear prediction function \(H\) is equal to zero (the thick solid line), 1, and -1 (the dotted lines). Each cell of the grid is 1 unit by 1 unit. The origin is not specified (it is not necssary to know the absolute coordinates of any points for this problem).
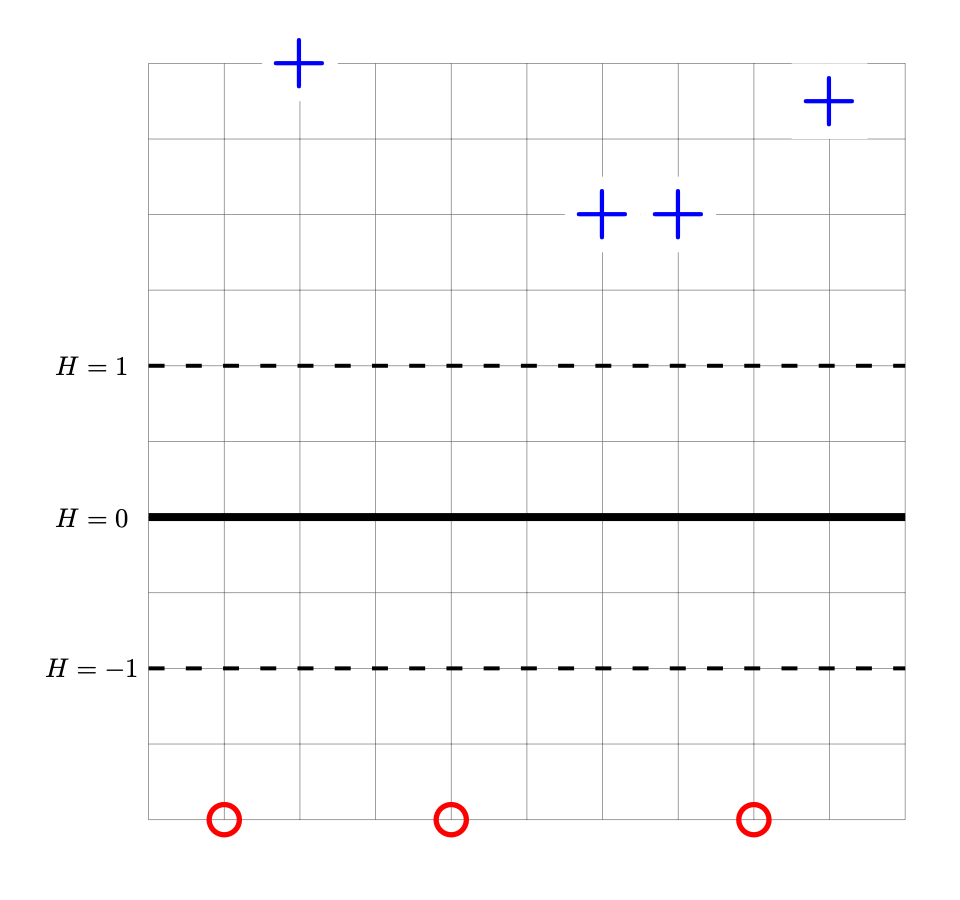
Suppose that the weight vector \(\vec w\) of the linear prediction function \(w_0 + w_1 x_1 + w_2 x_2\) shown above is \((6, 0, \frac{1}{2})^T\). This weight vector is not the solution to the Hard SVM problem.
What weight vector is the solution of the Hard SVM problem for this data set?
Solution
Although this decision boundary is in the right place, it can't be the solution to the Hard-SVM problem because its margin isn't maximized. Remember that the surface of \(H\) is a plane, and in this case the plane is too steep; we need to decrease its slope. We do this by scaling the weight vector by a constant factor; in this case, we want to double the margin, so we need to halve the slope. Therefore, the right answer is \(\frac{1}{2}(6, 0, \frac{1}{2})^T = (3, 0, \frac{1}{4})^T\).
Problem #087
Tags: SVMs
Let \(\mathcal X\) be a binary classification data set \((\nvec{x}{1}, y_1), \ldots, (\nvec{x}{n}, y_n)\), where each \(\nvec{x}{i}\in\mathbb R^d\) and each \(y_i \in\{-1, 1\}\). Suppose that the data in \(\mathcal X\) is linearly separable.
Let \(\vec w_{\text{svm}}\) be the weight vector of the hard-margin support vector machine (SVM) trained on \(\mathcal X\). Let \(\vec w_{\text{lsq}}\) be the weight vector of the least squares classifier trained on \(\mathcal X\).
True or False: it must be the case that \(\vec w_{\text{svm}} = \vec w_{\text{lsq}}\).
Solution
False.
Problem #088
Tags: SVMs
Recall that the Soft-SVM optimization problem is given by
where \(\vec w\) is the weight vector, \(\vec\xi\) is a vector of slack variables, and \(C\) is a regularization parameter.
The two pictures below show as dashed lines the decision boundaries that result from training a Soft-SVM on the same data set using two different regularization parameters: \(C_1\) and \(C_2\).
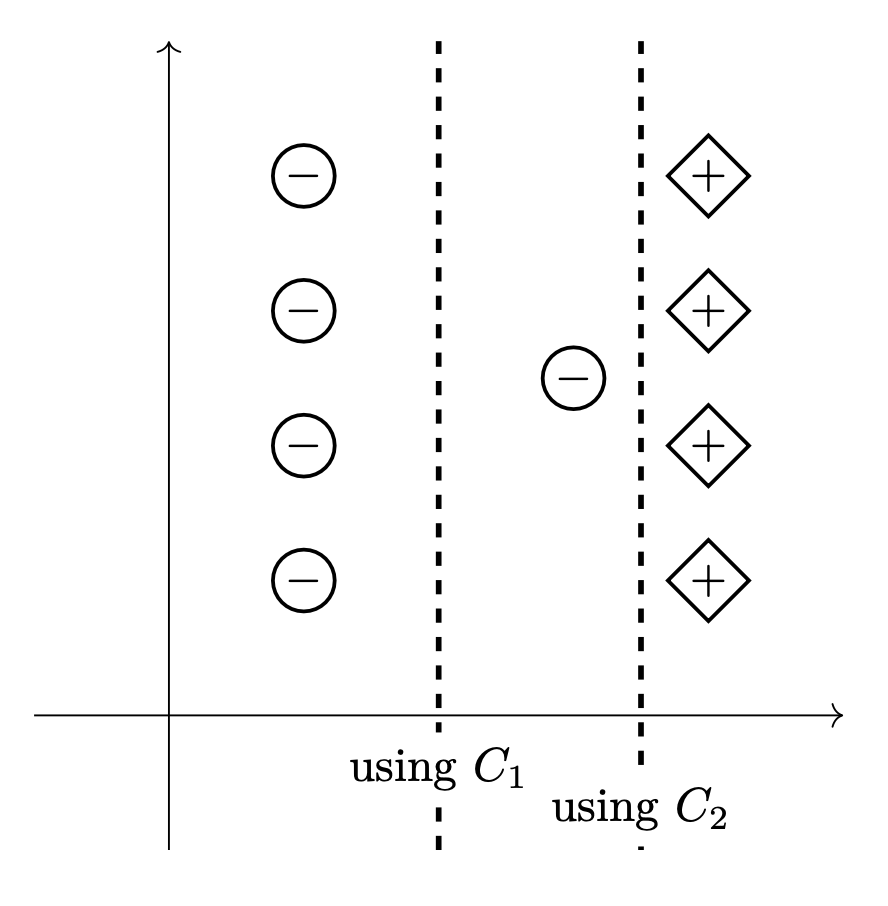
True or False: \(C_1 < C_2\).
Solution
True.
Problem #089
Consider the data set shown below. The points marked with ``+'' have label +1, while the ``\(\circ\)'' points have label -1. Shown are the places where a linear prediction function \(H\) is equal to zero (the thick solid line), 1, and -1 (the dotted lines). Each cell of the grid is 1 unit by 1 unit. The origin is not specified (it is not necssary to know the absolute coordinates of any points for this problem).
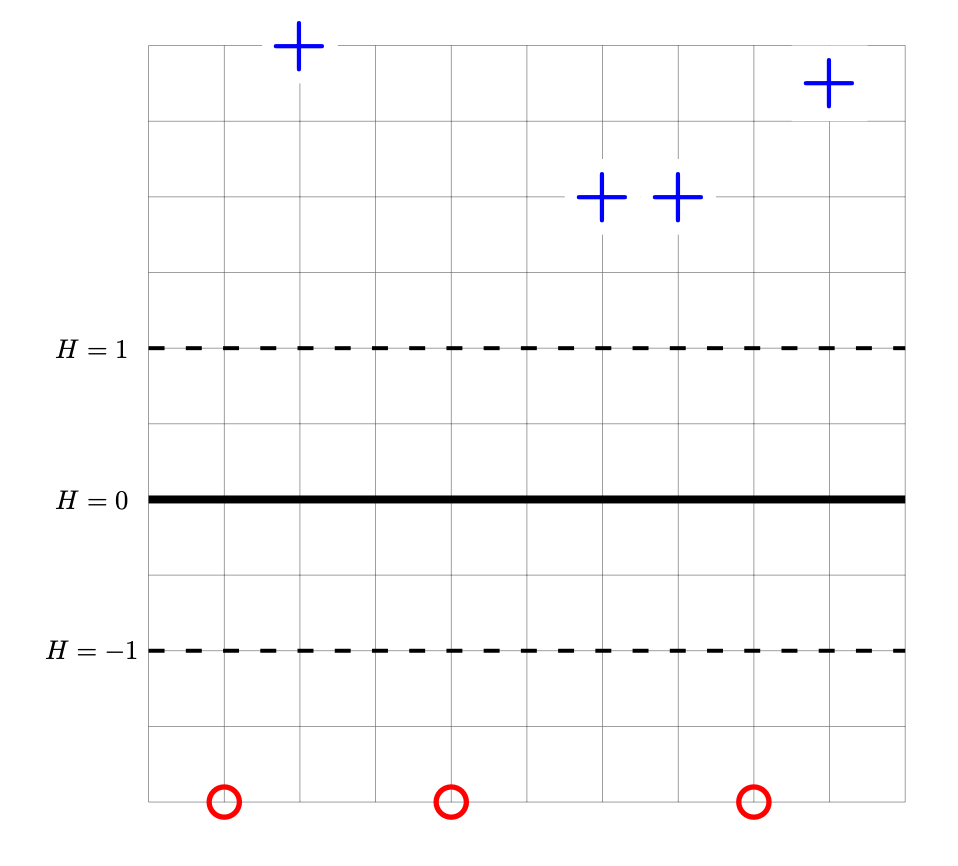
Let \(\vec w'\) be the parameter vector corresponding to prediction function \(H\) shown above. Let \(R(\vec w)\) be the risk with respect to the hinge loss on this data. True or False: the gradient of \(R\) evaluated at \(\vec w'\) is \(\vec 0\).
Solution
True.